







新用戶登錄后自動創建賬號
登錄第三方登錄



概述
互聯網公司同質應用服務競爭日益激烈,業務部門亟需利用線上實時反饋數據輔助決策支持以提高服務水平。Alluxio(前Tachyon)作為一個以內存為中心的虛擬分布式存儲系統,在大數據系統性能提升以及生態系統多組件整合的進程中扮演著重要角色。本文將介紹去哪兒網(Qunar)的一個基于Alluxio的實時日志流的處理系統,Alluxio在此系統中重點解決了異地數據存儲和訪問慢的問題,從而將生產環境中整個流處理流水線的性能總體提高了近10倍,而峰值時甚至達到300倍左右。
目前,去哪兒網的流處理流水線每天需要處理的業務日志量大約60億條,總計約4.5TB的數據量。其中許多任務都需要保證在穩定的低延時情況下工作,快速迭代計算出結果并反饋到線上業務系統中。例如,無線應用的用戶點擊、搜索等行為產生的日志,會被實時抓取并寫入到流水線中分析出對應的推薦信息,然后反饋給業務系統并展示在應用中。如何保證數據的可靠性以及低延時,就成了整個系統開發和運維工作中的重中之重。
Alluxio大數據存儲系統源自于UC Berkeley AMPLab,目前由Alluxio公司在開源社區主導開發。它是世界上第一個以內存為中心的虛擬的分布式存儲系統,并將多樣化的上層計算框架和底層存儲系統連接起來,統一數據訪問方式。Alluxio以內存為中心的存儲特性使得上層應用的數據訪問速度比現有常規方案快幾個數量級。此外,Alluxio提供的層次化存儲、統一命名空間、世系關系、靈活的文件API、網頁UI以及命令行工具等特性也方便了用戶在不同實際應用場景下的使用。在本文中,我們將結合具體案例做進一步地闡述。
在我們的案例中,整個流處理計算系統部署在一個物理集群上,Mesos負責資源的管理和分配,Spark Streaming和Flink是主要的流計算引擎;存儲系統HDFS位于另外一個遠端機房,用于備份存儲整個公司的日志信息;Alluxio則是作為核心存儲層,與計算系統部署在一起。業務流水線每天會產生4.5TB左右的數據寫入存儲層,同時通過Kafka消費大約60億條日志與存儲層中的數據進行碰撞分析。Alluxio對整個流處理系統帶來的價值主要包括:
利用Alluxio的分層存儲特性,綜合使用了內存、SSD和磁盤多種存儲資源。通過Alluxio提供的LRU、LFU等緩存策略可以保證熱數據一直保留在內存中,冷數據則被持久化到level 2甚至level 3的存儲設備上;而HDFS作為長期的文件備份系統。
利用Alluxio支持多個計算框架的特性,通過Alluxio實現Spark以及Zeppelin等計算框架之間的數據共享,并且達到內存級的文件傳輸速率;此外,我們計劃將Flink和Presto業務遷移到Alluxio上。
利用Alluxio的統一命名空間特性,便捷地管理遠程的HDFS底層存儲系統,并向上層提供統一的命名空間,計算框架和應用能夠通過Alluxio統一訪問不同的數據源的數據;
利用Alluxio提供的多種易于使用的API,降低了用戶的學習成本,方便將原先的整個系統遷移至Alluxio,同時也使得調整的驗證過程變得輕松許多;
利用Alluxio解決了原有系統中“Spark任務無法完成”的問題:原系統中當某個Spark executor失敗退出后,會被Mesos重新調度到集群的任何一個節點上,即使設置了保留上下文,也會因為executor的“漂泊”而導致任務無法完成。新系統中Alluxio將數據的計算與存儲隔離開來,計算數據不會因executor的“漂泊”而丟失,從而解決了這一問題。
本文剩余部分將詳細對比分析Qunar原有流處理系統以及引入Alluxio改進后的流處理系統,最后簡述我們下一步的規劃和對Alluxio未來方向的期待。
原有系統架構以及相關問題分析
我們的實時流處理系統選擇了Mesos作為基礎架構層(Infrastructure Layer)。在原先的系統中,其余組件都運行在Mesos之上,包括Spark、Flink、Logstash以及Kibana等。其中主要用于流式計算的組件為Spark Streaming,在運行時Spark Streaming向Mesos申請資源,成為一個Mesos Framework,并通過Mesos調度任務。
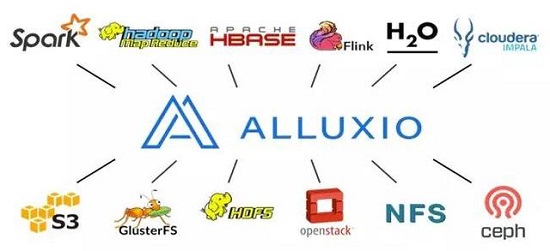
如上圖所示,在該流處理系統中,待處理的日志數據來自于多個數據源,由Kafka進行匯總,數據流在經過了Logstash集群清洗后再次寫入Kafka暫存,后續由Spark Streaming和Flink等流式計算框架消費這些數據,計算的結果寫入HDFS。在原先的數據處理過程中,主要存在著以下性能瓶頸:
用于存放輸入和輸出數據的HDFS位于一個遠程存儲集群中(物理位置上位于另一個機房)。本地計算集群與遠程存儲集群存在較高的網絡延遲,頻繁的遠程數據交換成為整個流處理過程的一大瓶頸;
HDFS的設計是基于磁盤的,其I/O性能,尤其是寫數據性能難以滿足流式計算所要求的延時;Spark Streaming在進行計算時,每個Spark executor都要從HDFS中讀取數據,重復的跨機房讀文件操作進一步地的拖慢了流式計算的整體效率;
由于Spark Streaming被部署在Mesos之上,當某個executor失效時,Mesos可能會在另一個節點重啟這個executor,但是之前失效節點的checkpoint信息不能再被重復利用,計算任務無法順利完成。而即便executor被重啟在同一節點上,任務可以完成時,完成的速度也無法滿足流式計算的要求。
在Spark Streaming中,若使用MEMORY_ONLY方式管理數據塊,則會有大量甚至重復的數據位于Spark executor的JVM中,不僅增大了GC開銷,還可能導致內存溢出;而如果采用MEMORY_TO_DISK或者DISK_ONLY的方式,則整體的流處理速度會受限于緩慢的磁盤I/O。
改進后的系統架構及解決方案
在引入Alluxio之后,我們很好地解決上述問題。在新的系統架構中,整個流式處理的邏輯基本不變。唯一變化的地方在于使用Alluxio代替原先的HDFS作為核心存儲系統,而將原來的HDFS作為Alluxio的底層存儲系統,用于備份。Alluxio同樣運行在Mesos之上,各個計算框架和應用都通過Alluxio進行數據交換,由Alluxio提供高速的數據訪問服務并維護數據的可靠性,僅將最終輸出結果備份至遠程HDFS存儲集群中。
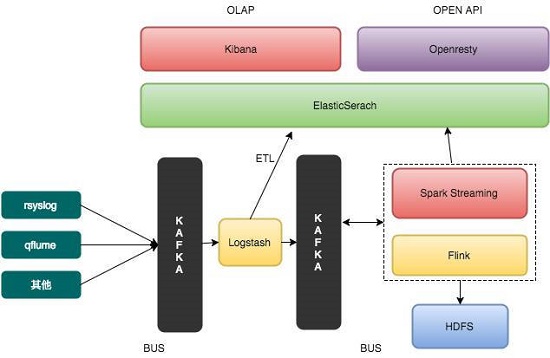
在新的系統架構中,最初的輸入數據仍然經過Kafka過濾,交由Spark Streaming消費,不同的是,Spark Streaming在計算時產生的大量中間結果以及最終的輸出都存放在Alluxio中,避免與較慢的遠程HDFS集群進行交互,同時,存放在Alluxio中的數據也能夠很方便地與上層組件,如Flink、Zeppelin進行共享。在整個過程中,Alluxio的一些重要特性對整個流水線的性能提升起到了重要的作用:
支持分層存儲——我們在每個計算節點上都部署了Alluxio Worker,管理了本地的存儲介質,包括內存、SSD和磁盤,構成了層次化的存儲層。每個節點上流計算相關的數據會被盡可能的存放在本地,避免消耗網絡資源。同時,Alluxio自身提供了LRU、LFU等高效的替換策略,能夠保證熱數據位于速度較快的內存層中,提高了數據訪問速率;即便是冷數據也是存放在本地磁盤中,不會直接輸出到遠程HDFS存儲集群;
跨計算框架數據共享——在新的系統架構中,除了Spark Streaming本身以外,其他組件如Zeppelin等也需要使用Alluxio中存放的數據。另外,Spark Streaming和Spark batch job可以通過Alluxio相連并從中讀取或寫入數據,來實現內存級別的數據傳輸。另外,我們還在將Flink相關的業務與邏輯遷移到Alluxio上,來實現計算框架間的高效數據共享;
統一命名空間——通過使用Alluxio分層存儲中HDD層,來管理計算集群本地的持久存儲,同時使用Alluxio的mount功能來管理遠程的HDFS存儲集群。Alluxio很自然地將HDFS以及Alluxio自身的存儲空間統一管理起來。這些存儲資源對于上層應用和計算框架透明的,只呈現了一個統一的命名空間,避免了復雜的輸入輸出邏輯;
簡潔易用的API——Alluxio提供了多套易用的API,它的原生API是一套類似java.io的文件輸入輸出接口,使用其開發應用不需要繁雜的用戶學習曲線;Alluxio提供了一套HDFS兼容的接口,即原先以HDFS作為目標存儲的應用程序能夠直接遷移至Alluxio,應用程序僅僅需要將原有的hdfs://替換成alluxio://就能正常工作,遷移的成本幾乎是零。此外,Alluxio的命令行工具以及網頁UI方便了開發過程中的驗證和調試步驟,縮短了整個系統的開發周期。例如我們使用Chronos(一個Mesos的Framework,用來執行定時任務)在每天的凌晨通過Alluxio loadufs命令提前加載前一天由MapReduce計算好的數據到Alluxio中,以便后續的操作可以直接讀取這些文件。
Alluxio與Spark有著緊密的結合,我們在Spark Streaming將主要數據存放在Alluxio中而不是Spark executor的JVM中,由于存儲位置同樣是本地內存,因此不會拖慢數據處理的性能,反而能夠降低Java GC的開銷。同時,這一做法也避免了因同一節點上數據塊的冗余而造成的內存溢出。我們還將SparkSteaming計算的中間結果即對RDD的checkpoint存儲在Alluxio上。
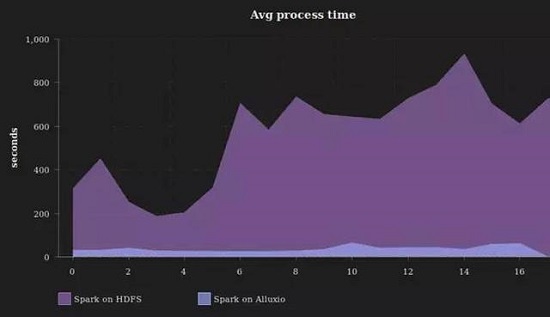
通過利用Alluxio眾多特性以及將數據從遠程HDFS存儲集群預取至本地Alluxio等優化方式,整個流處理流水線中的數據交互過程大量轉移到本地集群的內存中,從而極大地提升了數據處理的整體吞吐率,降低了響應延時,滿足了流處理的需求。從我們的線上實時監控的每次micro batch(間隔10分鐘)的監控圖中,可以看到平均處理吞吐量從由以前單個mirco batch周期內20至300的eps,提升到較為穩定的7800eps,平均的處理時間從8分鐘左右降低到30至40秒以內,整個流處理加速16-300倍。尤其是在網絡繁忙擁擠時,上百倍的加速效果尤為明顯。
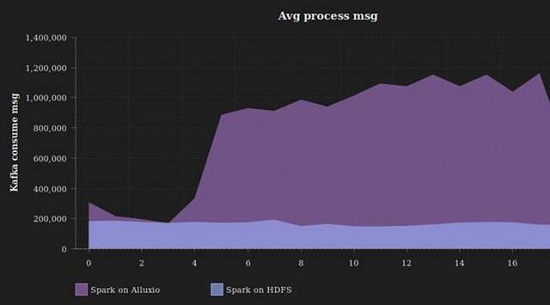
而對Kafka的消費指標來看,消費速度也從以前的200K條消息穩定提升到將近1200K。
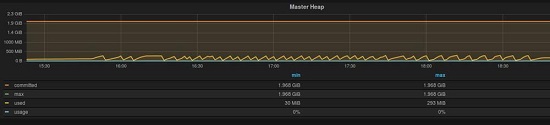
此外,我們利用Alluxio自帶的metrics組件將監控數據發送到graphite,以方便來監控Alluxio的JVM以及Alluxio的FileSystem狀態。可以看到Alluxio Master對Heap內存占用率維持在低水平。
同期的文件數量和操作統計為下圖所示。

未來展望
本文介紹的優化方法主要是針對利用Alluxio來解決異地存儲訪問慢的問題。性能提升的工作是永無止境的,最后我們也總結了一些未來的工作:
我們線上環境中目前使用的Alluxio的版本是0.8.2,Spark Streaming計算的結果目前只能同步寫入底層存儲系統(在我們的案例中即為HDFS),我們已經測試了Alluxio 1.0.1 并準備上線新版本,得益于Alluxio社區活躍的開發,新版本的性能在很多方面都有更大的提升。
我們計劃將Flink的計算任務也遷移至Alluxio,同時我們也在計劃修改Presto,令其可以同樣享受Alluxio帶來的跨計算引擎高速數據共享的功能;
由于Alluxio能夠很容易于現有存儲系統進行整合并提升上層業務的性能,因此我們也將推廣Alluxio到更多的業務線中,例如用于分析日志數據的批處理任務等。
【號外】以“融合·新生態”為主題的《執惠·2016中國旅游大消費創新峰會》將于6月16日在國家會議中心舉行,屆時國內旅游、投資、體育、營銷、娛樂、媒體、戶外等近千名各界精英將齊聚一堂,直擊旅游大消費產業前沿,探索廣闊未來,分享最具創新性的產品體驗,聚合最優質的投資與營銷資源,積聚能量,共創價值。歡迎點擊鏈接查看詳情并報名:http://m.gzvtc-edu.com/activity/new-eco#join


掃碼查看詳情

掃碼關注執惠公眾號